API flow testing for onboarding and checkout
How to design multi-step API flow testing for onboarding, checkout, auth, and webhooks using Markdown pipeline specs with captures and injections.
API flow testing catches the bugs that endpoint tests miss. A user can be created successfully, a session can be issued successfully, and an order can be created successfully, while the complete onboarding or checkout journey still fails.
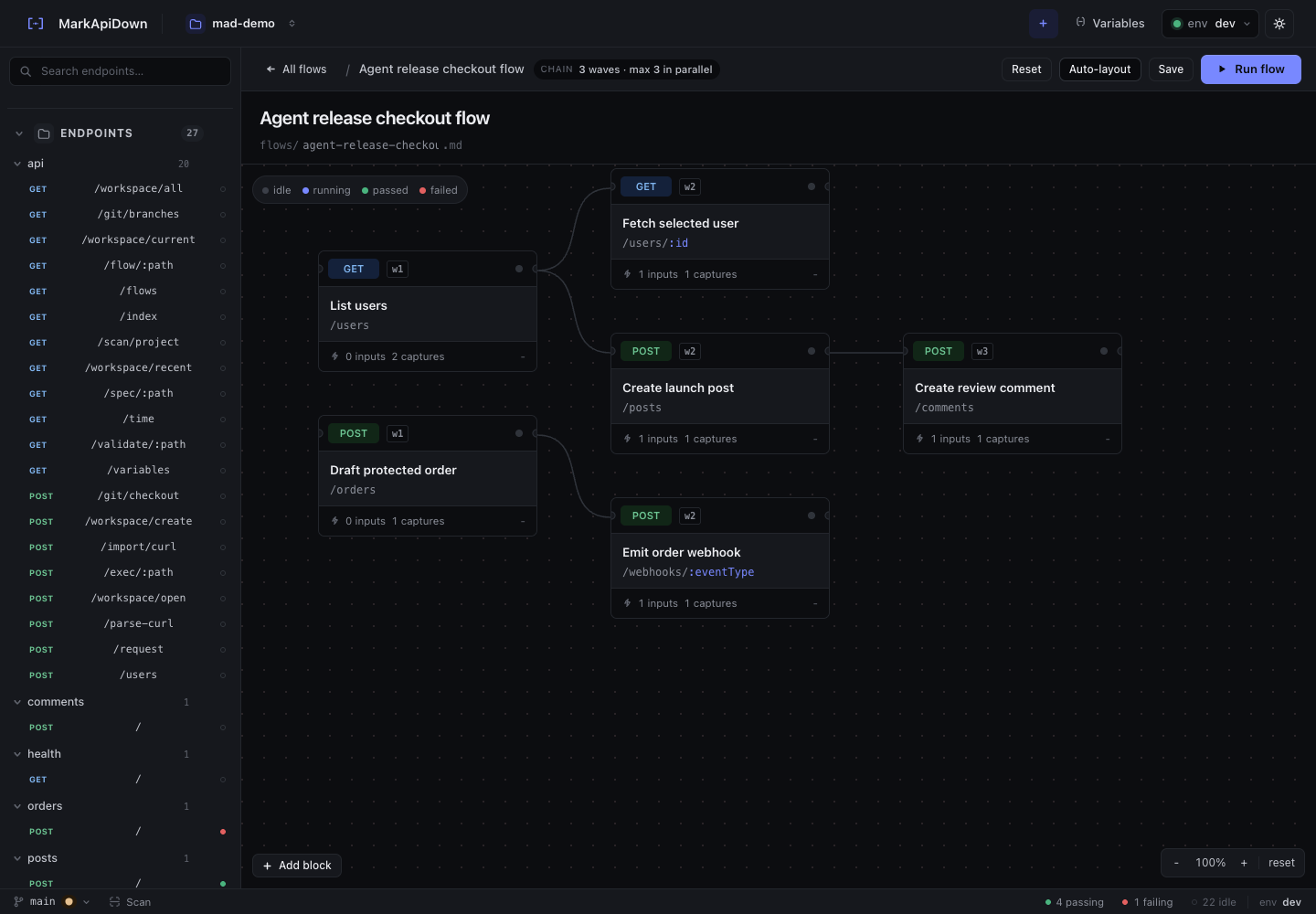
Reqbook models those journeys as Markdown pipeline files under api-docs/flows/.
One endpoint test is not a user journey
Endpoint specs are necessary. They keep individual API contracts honest. But product behavior often spans multiple calls:
- create a user,
- log in,
- create a cart,
- start checkout,
- receive a webhook,
- fetch the final order state.
Testing those calls independently does not prove the journey works. The risky part is the handoff between calls: IDs, tokens, state transitions, webhook payloads, and timing assumptions.
That is what a pipeline should protect.
Capture once, inject later
A Reqbook flow captures values from one response and injects them into later steps.
---
type: pipeline
name: onboarding-checkout
description: Create a user, create an order, and verify checkout state.
continue-on-error: false
parallel: false
---
# Onboarding checkout
## Steps
1. **Create user** -> `apis/users/post-users.md`
- Capture: `response.body.id` as `userId`
2. **Create order** -> `apis/orders/create-order.md`
- Inject: `userId`
- Capture: `response.body.id` as `orderId`
3. **Receive checkout webhook** -> `apis/webhooks/receive-event.md`
- Inject: `orderId`
- Assert: `response.status == 200`The capture is not just a convenience. It makes the dependency explicit. A reviewer can see that the order step depends on the user step, and the webhook step depends on the order step.
Design flows around business risk
Do not make one giant flow for the whole product. Long flows are hard to debug and easy to ignore.
Create flows around business risk:
| Flow | What it protects |
|---|---|
signup-login-profile | Account creation and auth handoff |
onboarding-checkout | First purchase path |
subscription-renewal | Billing state transitions |
webhook-replay | Idempotency and event handling |
device-pairing | Token exchange and user ownership |
Each flow should be short enough that a failed step has an obvious owner.
Debugging a failed flow
When a flow fails, the most useful output is not “step 3 failed.” The useful output is:
- which captured values exist,
- which injected value was missing,
- whether the response mismatched the expected contract,
- whether the error was auth, network, validation, or a behavior change.
That is why Reqbook uses structured flow results in the CLI and MCP tools.
rqb flow api-docs/flows/onboarding-checkout.md --env=dev --output=jsonA coding agent can inspect that JSON and decide whether to update implementation code, update the expected response, or ask for a missing variable.
Sequential by default, parallel only when independent
Most onboarding and checkout flows should run sequentially. The later steps depend on IDs, tokens, or state created by earlier steps.
Use parallel execution only for independent setup steps. For example, creating a product fixture and creating a coupon fixture can happen in parallel if neither step needs the other’s response.
The rule is simple:
- if a step uses
Inject, keep it after the step that produces the capture; - if a step changes shared state, keep the flow sequential;
- if a step creates independent fixtures, parallel execution can save time;
- if debugging becomes confusing, prefer sequential execution.
Fast tests are useful. Understandable failures are more useful.
Use the browser UI while designing the flow
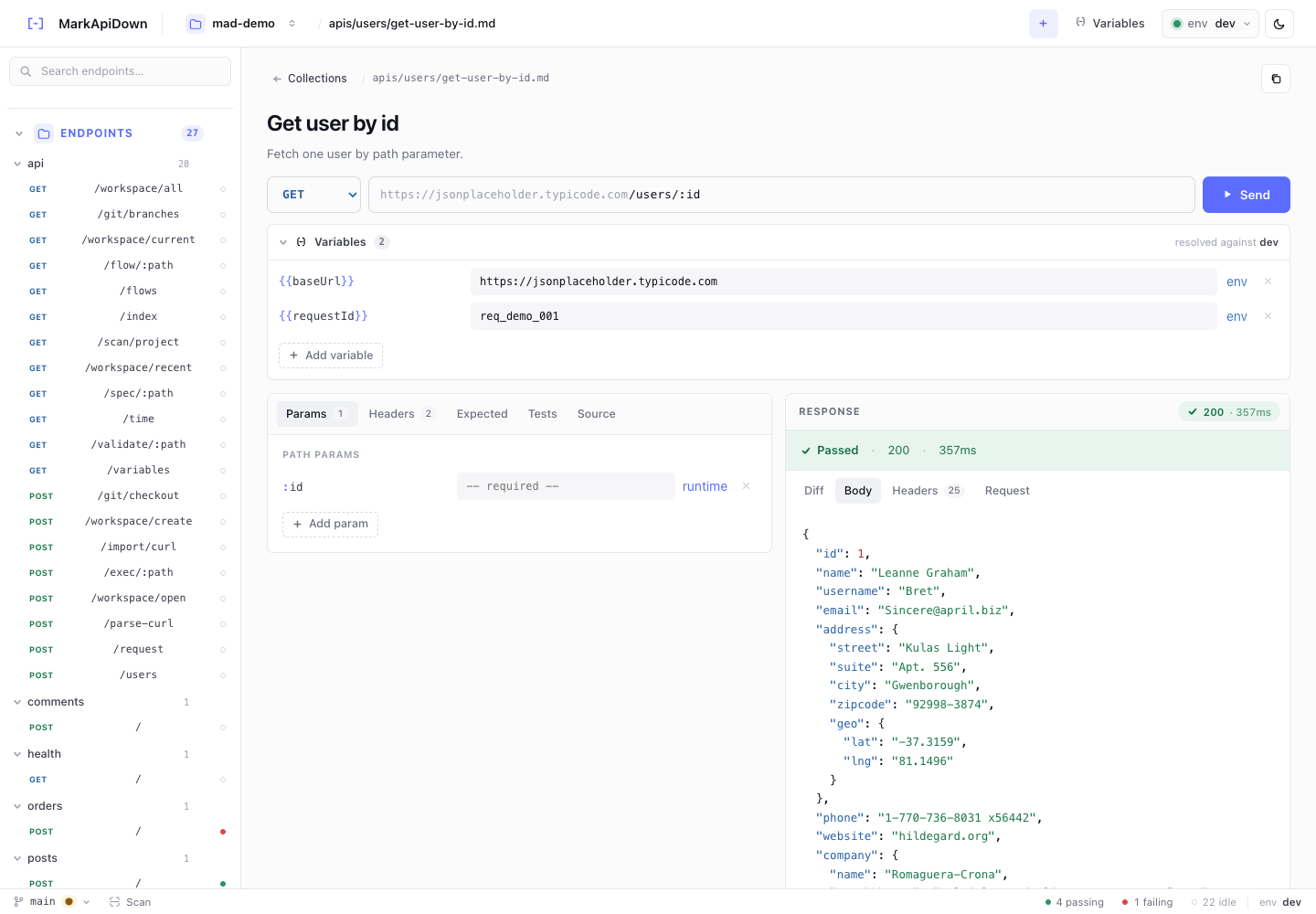
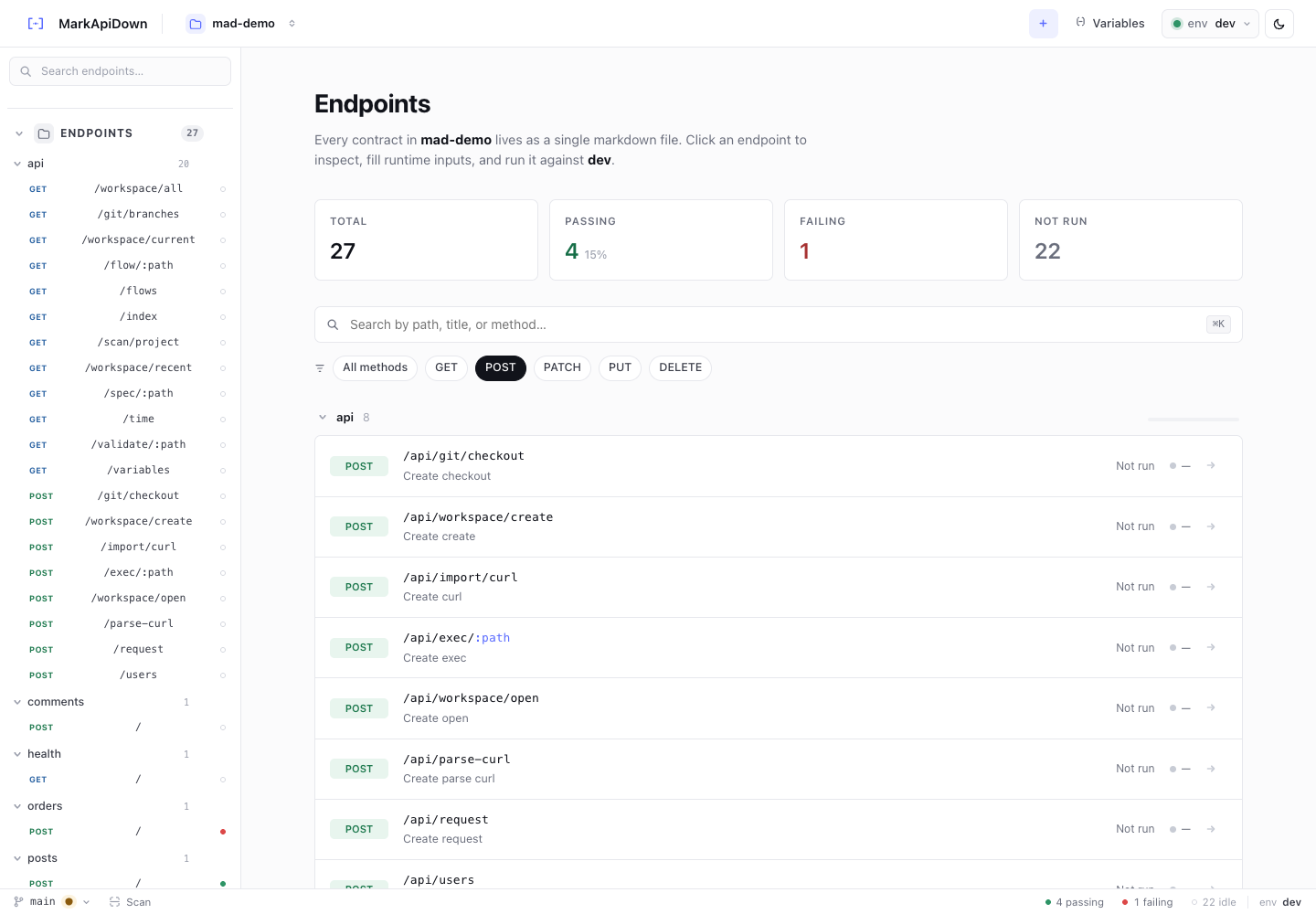
Markdown is the source of truth, but a visual UI helps while designing a flow. Open the browser workspace:
rqb serveUse it to inspect the endpoint list, verify request shapes, and confirm which values should be captured between steps. Then commit the pipeline file so the flow can run from CLI, CI, and MCP.
That pattern keeps human exploration and automation aligned:
- explore the flow visually,
- encode it as Markdown,
- run it in CI,
- let agents execute it through MCP.
The screenshot in this article shows the endpoint browser because that is where many teams discover the first flow candidate. If a group of endpoints always changes together, it probably deserves a pipeline.
Keep fixtures explicit
Flow tests become flaky when setup is implicit. If a checkout flow requires a user, product, cart, and payment method, the flow should either create them or name the assumptions clearly.
Bad assumption:
Run checkout against whatever user exists in staging.Better contract:
Create user -> capture userId
Create product -> capture productId
Create cart -> inject userId and productId
Start checkout -> capture checkoutSessionId
Verify webhook -> inject checkoutSessionIdExplicit setup makes the flow slower than a single endpoint test, but much more reliable as a business guardrail.
Decide what a failed flow should block
Not every flow needs to block every pull request. Treat flows by risk:
| Flow type | Suggested gate |
|---|---|
| Smoke flow | Every pull request touching API code |
| Checkout or billing flow | Pull requests and release branches |
| Long regression flow | Nightly or pre-release |
| Third-party webhook flow | Staging or scheduled job |
This avoids turning flow testing into a wall of red builds. The goal is confidence, not maximum noise.
When a flow does block a PR, it should point to the failing step and the contract file. The developer should not have to reconstruct the user journey from CI logs.
Assert the handoff, not every byte
Flow assertions should focus on the values that prove the journey worked. For onboarding, that might be userId, authToken, and profile status. For checkout, it might be orderId, payment state, and webhook acknowledgement.
Avoid asserting every timestamp, generated URL, or incidental response field. Those fields make flows brittle without improving confidence. Start with the handoff values, then add stricter assertions only where business risk justifies it.
The best flow test reads like the product path it protects. A reviewer should understand the journey from the step names before reading the response body.
For CI usage, read CI API testing with Markdown specs. For agent usage, read MCP API testing for AI agents.