API docs as code: executable contracts in your repo
A practical guide to API docs as code using Markdown contracts that developers can review, coding agents can read, and CI can execute.
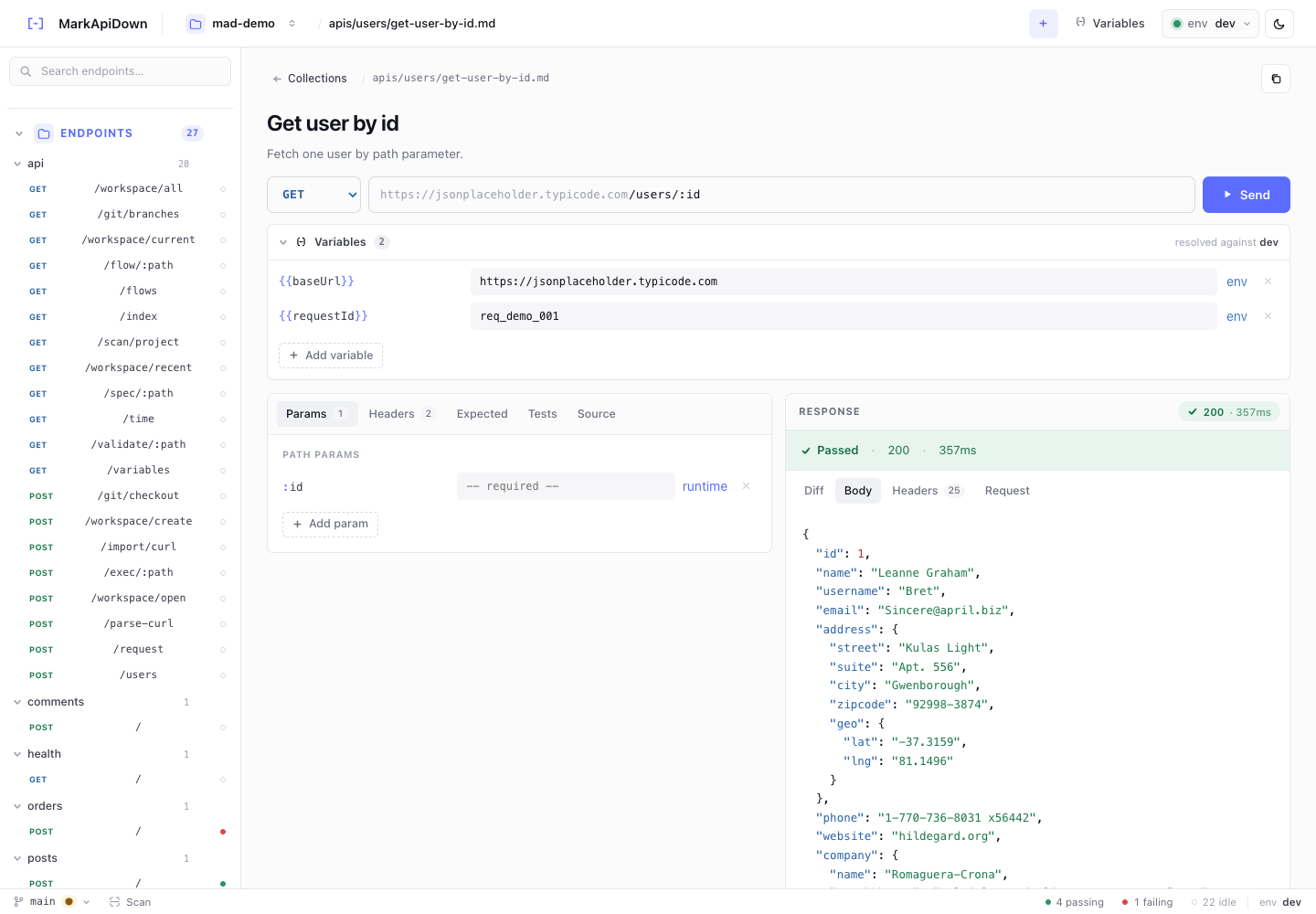
API docs as code is strongest when the documentation is not just stored beside the code. It also needs to run beside the code.
That is the difference Reqbook is built around. A Markdown API spec is readable in a pull request, searchable by a coding agent, editable in a browser UI, and executable from the CLI. The same file can explain an endpoint, validate a response, and leave a reviewable artifact when behavior changes.
Docs as code only works if the docs can run
Most teams already have some form of API docs as code. The docs might live in docs/, a README, OpenAPI YAML, a collection export, or comments near route handlers. That helps with ownership, but it does not automatically prevent drift.
The drift happens because the documentation and the verification are still separate:
- A README shows an example request.
- A unit test checks a handler detail.
- A GUI collection stores a manual request.
- CI runs a different smoke test.
- A coding agent reads whatever file it finds first.
Reqbook compresses that surface area into one contract file.
# Create workspace
Creates a workspace for a new customer account.
## Request
```http
POST {{baseUrl}}/workspaces
Content-Type: application/json
{
"name": "{{workspaceName}}",
"plan": "team"
}
```
## Expected response
```http
HTTP/1.1 201 Created
Content-Type: application/json
{
"id": "{{workspaceId}}",
"name": "{{workspaceName}}"
}
```
## Assertions
- status: 201
- body.id: existsThis is documentation a person can read. It is also a contract a machine can run.
What belongs in the repo
A useful repo-native API documentation system needs a boring, predictable file layout. Reqbook uses plain files under api-docs/:
api-docs/
reqbook.md
_shared/env.md
apis/workspaces/post-create-workspace.md
apis/users/get-user-by-id.md
flows/onboarding-checkout.mdThe important part is not the exact folder names. The important part is that the files can be reviewed with the same discipline as source code.
When an API change ships, reviewers should be able to ask:
- Did the request example change?
- Did the expected response change?
- Are variables still resolved safely?
- Did the flow that depends on this endpoint still pass?
- Can a coding agent discover the contract without guessing?
That is a different quality bar from “the docs page was updated later.”
The review loop
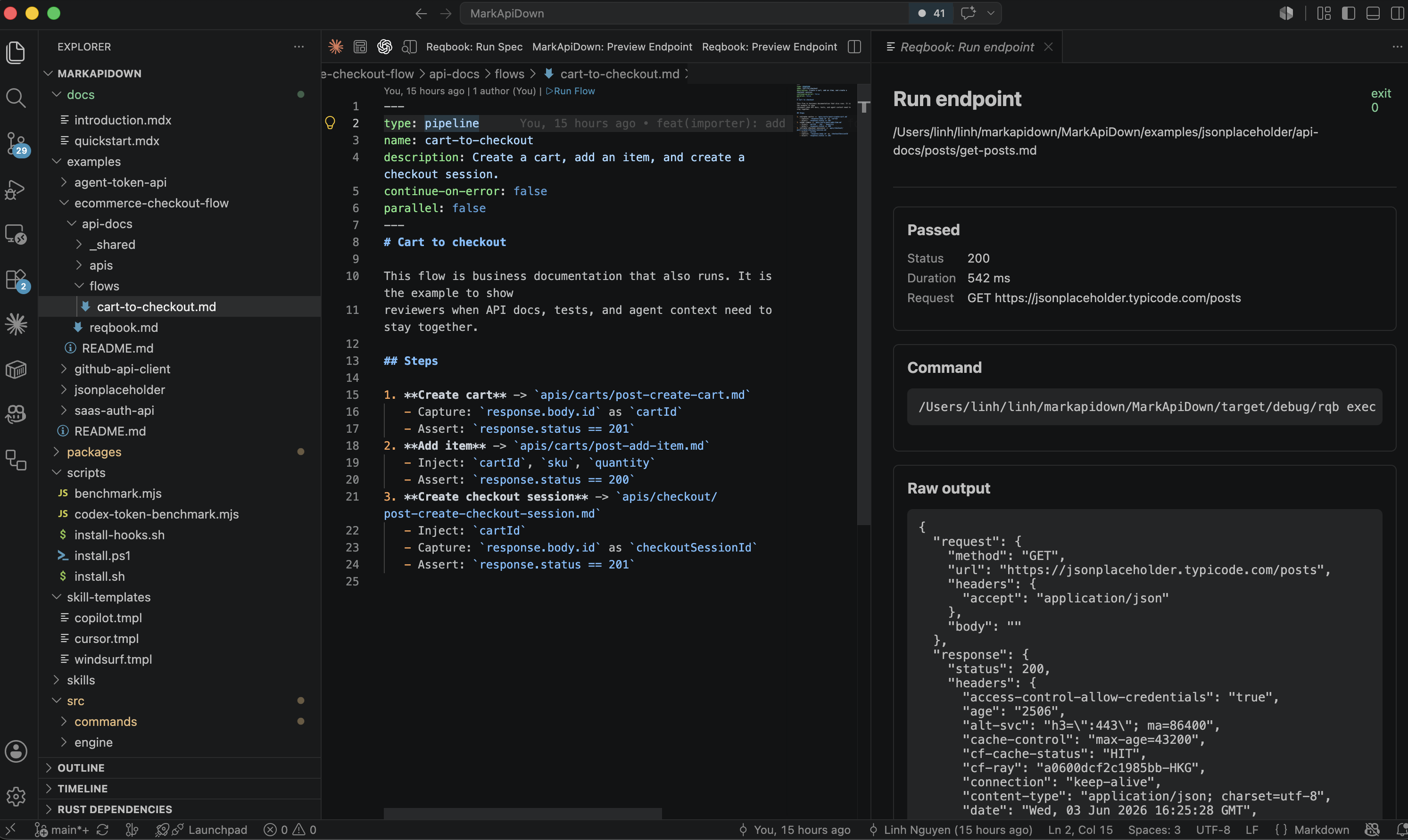
A healthy API docs as code loop looks like this:
rqb validate api-docs/
rqb exec api-docs/apis/workspaces/post-create-workspace.md --env=dev
rqb flow api-docs/flows/onboarding-checkout.md --env=devrqb validate catches structural problems before a network request is sent. rqb exec checks one endpoint. rqb flow checks a multi-step product journey.
The pull request should show the contract diff and the implementation diff together. If the response changed intentionally, the expected response changes too. If the response changed accidentally, the contract catches it before the change becomes tribal knowledge.
Where the browser UI fits
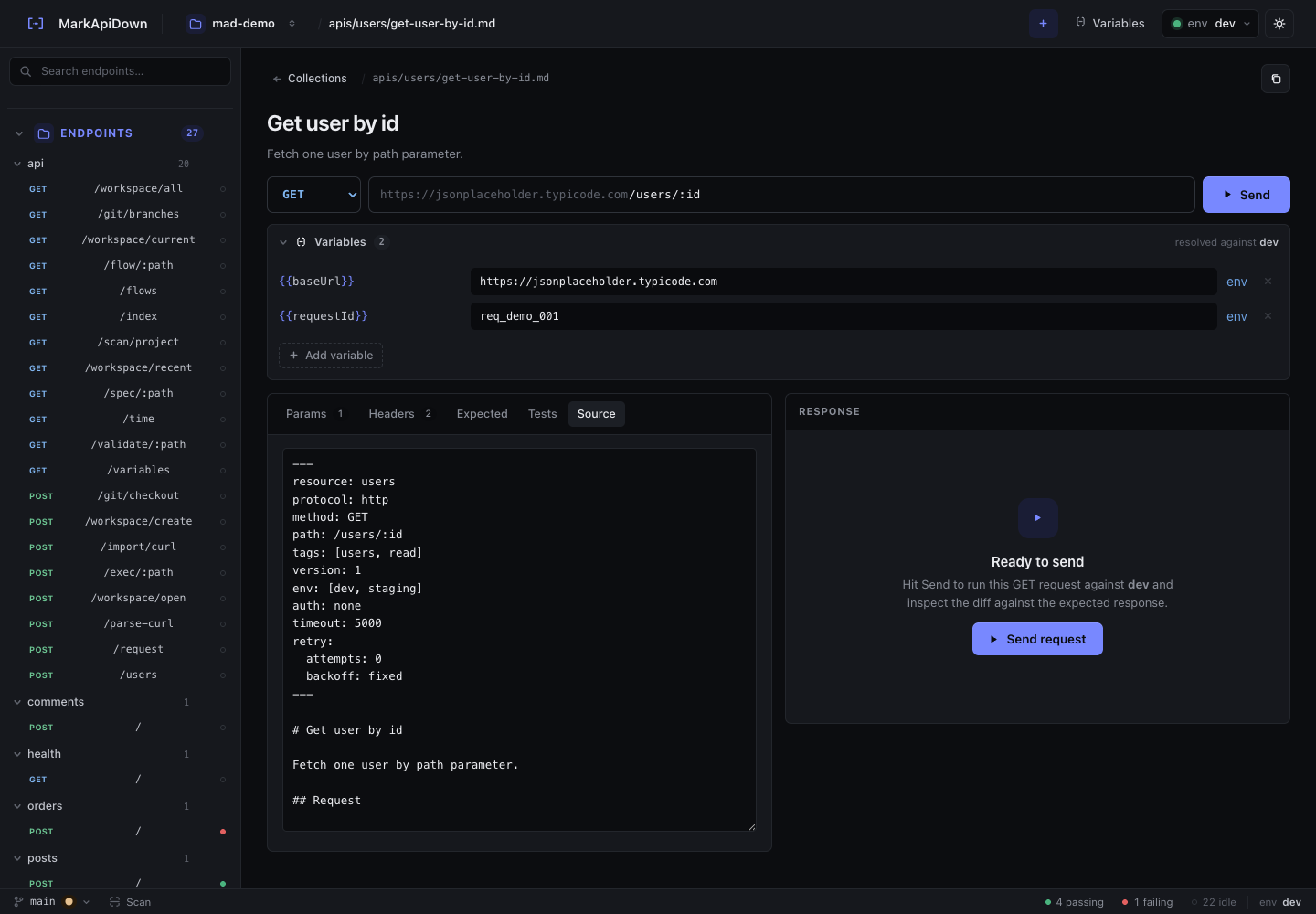
Docs as code does not mean every workflow has to happen in a terminal. The Reqbook browser UI exists for inspection, local runs, search, variables, and visual flow work.
That matters because API contracts have multiple audiences:
- A backend engineer wants fast CLI feedback.
- A reviewer wants a readable diff.
- A frontend engineer wants to inspect request and response shape.
- A coding agent wants compact context and executable tools.
- CI wants deterministic exit codes.
One Markdown contract can serve all of them when the UI and CLI are just two views over the same files.
How to migrate without freezing the team
The safest migration path is not to rewrite every API document in one sprint. Start with the endpoint that creates the most review noise.
Good first targets are:
- a login endpoint with auth variables,
- a create endpoint with a stable response shape,
- a webhook handler with strict status expectations,
- a checkout or onboarding step that already breaks in staging,
- an endpoint a coding agent often needs before changing product code.
Move one request into api-docs/, write the expected response, and run it locally:
rqb exec api-docs/apis/workspaces/post-create-workspace.md --env=devThen add it to CI only after the local contract is stable. This keeps the migration boring. The goal is not to prove that every endpoint is covered on day one. The goal is to establish a repeatable pattern the team trusts.
Once the first spec is working, use the same pull request template for every API change:
API change checklist
- [ ] Implementation updated
- [ ] Markdown contract updated
- [ ] Expected response still matches intentional behavior
- [ ] Variables resolve in dev or staging
- [ ] Relevant flow still passesThat checklist is small, but it changes the review conversation. Reviewers stop asking whether docs will be updated later. The docs are in the diff.
What not to put in a contract file
API docs as code should not become a dumping ground. A contract file should contain the behavior needed to understand and verify one endpoint. It should not contain:
- production tokens,
- long debugging transcripts,
- implementation-only notes that belong in source comments,
- unstable response fields such as timestamps unless they are asserted carefully,
- environment-specific URLs hardcoded into the request.
Put non-secret environment values in _shared/env.md, local secrets in .env.local, and CI secrets in RQB_* variables. Keep the spec focused on the API behavior that should survive across environments.
This makes the contract more useful to agents too. A coding agent does not need a novel. It needs stable request shape, expected response shape, variables, assertions, and notes that explain business rules.
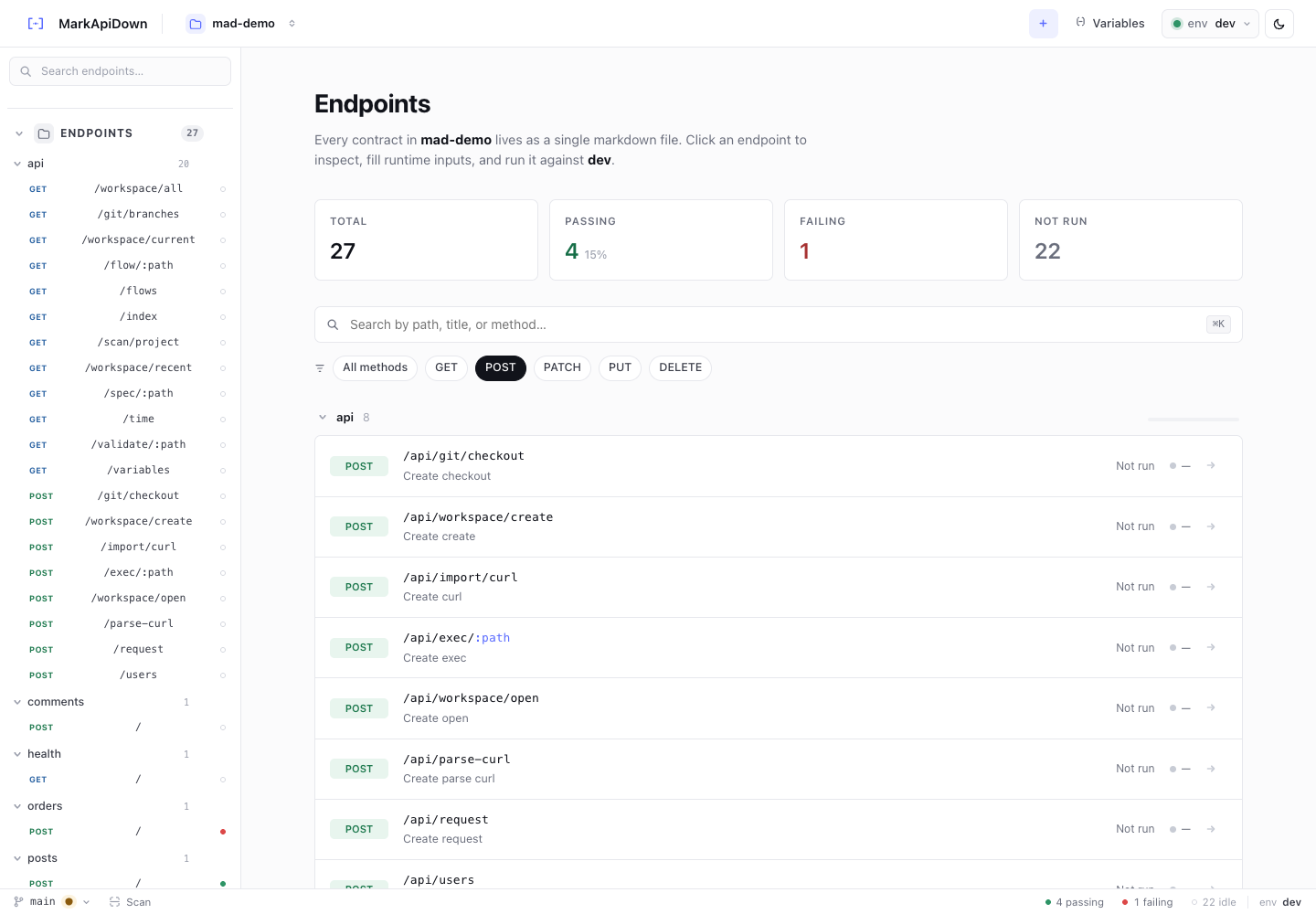
Measure coverage by workflow, not by endpoint count
Endpoint count is an easy metric, but it can be misleading. A project might have 200 documented endpoints and still miss the one checkout flow that matters.
A better coverage model has three layers:
| Layer | Question |
|---|---|
| Endpoint contracts | Can this single request run and verify its response? |
| Flow contracts | Does the user journey work across multiple endpoints? |
| Agent context | Can an agent find and execute the right contract before editing code? |
For a young project, cover the riskiest flows first. For a mature project, add endpoint coverage around areas that change often. For an agent-heavy team, prioritize endpoints that agents repeatedly rediscover from source code.
The practical outcome is a repo where API knowledge is not scattered. The API contract lives where developers already review work: in files, commits, and pull requests.
For the agent-specific workflow, read API testing for coding agents. For CI usage, continue with CI API testing with Markdown specs or jump to the install section.